Using the timescaledb extension
timescaledb (https://docs.timescale.com/latest/) is a postgresql extension for time-series database. Considering a lot of the actions done on datagrepper involve the timestamp field (for example: all the messages with that topic in this time range), we figured this extension is worth investigating.
A bonus point being for this extension to already packaged and available in Fedora and EPEL.
Resources
Setting up/enabling timescaledb: https://severalnines.com/database-blog/how-enable-timescaledb-existing-postgresql-database
Migrating an existing database to timescaledb: https://docs.timescale.com/latest/getting-started/migrating-data#same-db
Installing/enabling/activating
To install the plugin, simply run:
dnf install timescaledb
The edit /var/lib/pgsql/data/postgresql.conf to tell postgresql to load it:
shared_preload_libraries = 'pg_stat_statements,timescaledb'
timescaledb.max_background_workers=4
It will then need a restart of the entire database server:
systemctl restart postgresql
You can then check if the extension loaded properly:
$ sudo -u postgres psql
SELECT * FROM pg_available_extensions ORDER BY name;
Then, you will need to activate it for your database:
$ sudo -u postgres psql <database_name>
CREATE EXTENSION IF NOT EXISTS timescaledb CASCADE;
Finally, you can check that the extension was activated for your database:
$ sudo -u postgres psql <database_name>
\dx
Findings
Partitioned table
After converting the messages table to use timescaledb, we’ve realized that timescaledb uses table partitioning as well. This leads to the same issue with the foreign key constraints that we have seen in the plain partitioning approach we took.
Foreign key considerations
For a better understanding on the challenges we’ve encountered with foreign key constraints, here is a graphical representation of the datanommer database:
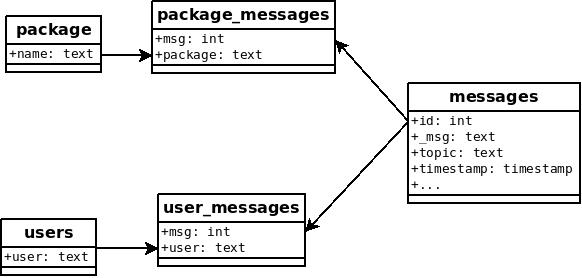
So here are the issues we’ve faced:
To make the messages table a hypertable (ie: activate the timescaledb plugin on it), the tables need to be empty and the data imported in a second step.
Once the messages table is a hypertable, we cannot add foreign key constraints from the user_messages or package_messages tables to it. It is just not supported in timescaledb (cf https://docs.timescale.com/latest/using-timescaledb/schema-management#constraints )
We tried creating the foreign key constraints before making the messages table a hypertable and then importing the data in (tweaking the primary key and foreign keys to include the timestamp, following https://stackoverflow.com/questions/64570143/ ) but that resulted in an error when importing the data.
So we ended up with: Keep the same data structure but to not enforce the foreign key constaints on user_messages and package_messages to messages. As that database is mostly about inserts and has no updates or deletes, we don’t foresee much problems with this.
Duplicated messages
When testing datagrepper and datanommer in our test instance with the timescaledb plugin, we saw a number of duplicated messages showing up in the /raw endpoint. Checking if we could fix this server side, we found out that the previous database schema had an UNIQUE constraint on msg_id field. However, with the timescaledb plugin, that constraint is now on both msg_id and timestamp fields, meaning a message can be inserted twice in the database if there is a little delay between the two inserts.
However, migrating datanommer from fedmsg to fedora-messaging should resolve that issue client side as rabbitmq will ensure there is only one consumer at a time handling a message.
Open questions
How will upgrading the postgresql version with the timescaledb plugin look like?
It looks like the timescaledb folks are involved enough in postgresql itself that we think things will work, but we have not had on-hands experience with it.
Patch
Here is the patch that needs to be applied to datanommer/models/__init__.py to get
it working with timescaledb’s adjusted postgresql model.
diff --git a/datanommer.models/datanommer/models/__init__.py b/datanommer.models/datanommer/models/__init__.py
index ada58fa..7780433 100644
--- a/datanommer.models/datanommer/models/__init__.py
+++ b/datanommer.models/datanommer/models/__init__.py
@@ -192,11 +192,11 @@ def add(envelope):
# These two blocks would normally be a simple "obj.users.append(user)" kind
# of statement, but here we drop down out of sqlalchemy's ORM and into the
# sql abstraction in order to gain a little performance boost.
- values = [{'username': username, 'msg': obj.id} for username in usernames]
+ values = [{'username': username, 'msg': obj.id, 'timestamp': timestamp} for username in usernames]
if values:
session.execute(user_assoc_table.insert(), values)
- values = [{'package': package, 'msg': obj.id} for package in packages]
+ values = [{'package': package, 'msg': obj.id, 'timestamp': timestamp} for package in packages]
if values:
session.execute(pack_assoc_table.insert(), values)
@@ -279,14 +279,17 @@ class BaseMessage(object):
source_version=self.source_version,
)
+
user_assoc_table = Table('user_messages', DeclarativeBase.metadata,
Column('username', UnicodeText, ForeignKey('user.name')),
- Column('msg', Integer, ForeignKey('messages.id'))
+ Column('msg', Integer, ForeignKey('messages.id')),
+ Column('timestamp', Integer, ForeignKey('messages.timestamp')),
)
pack_assoc_table = Table('package_messages', DeclarativeBase.metadata,
Column('package', UnicodeText, ForeignKey('package.name')),
Column('msg', Integer, ForeignKey('messages.id'))
+ Column('timestamp', Integer, ForeignKey('messages.timestamp')),
)